DAX “Filter Context” Explained

Do your DAX measures return interesting values but not the numbers you want? If the answer is yes, and it happens to all of us, then the problem probably lies with the filter context in which the measures have been calculated and the fact that you haven’t correctly identified them.
When a DAX measure is calculated in the “Values” bucket of a Power BI visual, whether it’s a column chart, pie chart, table , matrix or indeed any other visual, it is calculated within the filters that are affecting the choice of fields in that Visual. In other words, we can say that all DAX measures return a single value that’s evaluated in a specific filter context. To understand what is meant by a “specific filter context”, let’s compare these two different measures:-
Total Cases = SUM ( Winesales[CASES SOLD] )
Total Stores = SUM ( Customers[NO OF STORES] )
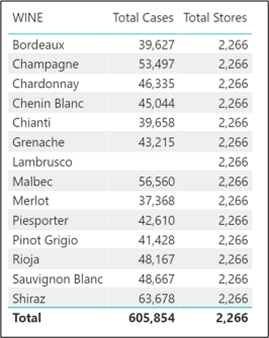
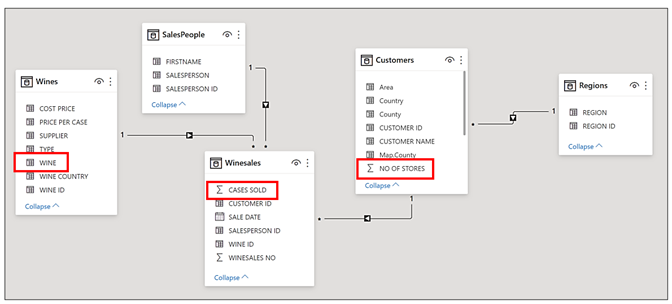
Because the evaluation of a DAX measure and the structure of the Data Model are inextricably linked, let’s also look at the Data Model we’re using. I’ve highlighted in red the relevant columns used in the two measures above. We’re using the WINE column in the Wines table in the Table Visual above and summing the CASES SOLD column in the Winesales table in the first measure and summing the NO OF STORES in the Customers table in the second measure.
Looking at these measures, why does the first measure return different values for each wine, but the second measure return the same value? The reason is the filter context that’s active when both these measures are evaluated.
Let’s explain what we mean by this. When a measure is placed into a visual, whether it’s a Column Chart, Table or any other visual, before the measure is evaluated, the DAX engine in memory places filters on tables in the Data Model depending on three factors:-
- Which column or columns in the visual are being used to group the data?
- Which columns in slicers are filtering the data in the visual?
- What filters in the Filters pane are filtering data in the visual?
These three factors come together to generate the “filter context” for the evaluation of the measure. We can’t see these filters on the Data Model. We just have to imagine them.
Note: Because the filtering of the Data Model happens in memory and is hidden from us, in the examples below where we’re simulating what happens in memory, I’ve coloured the tables yellow to distinguish them from the tables you can see in Data View.
In our table visual above, only factor #1 is relevant (there are no slicers or other filters). The column in the visual that’s grouping the data is the WINE column from the Wines dimension. The first value in this column to be calculated is total cases for “Bordeaux”.
Before the “Total Cases” measure calculates the value for “Bordeaux”, a filter is placed in memory on the Wines dimension to filter “Bordeaux” wines. If we could “see” the filter on this table, it would look like something like this:-

If we look at the Data Model, we can see that the Wines dimension is related to Winesales fact table in a many-to-one relationship. The arrow tells us that if the Wines dimension is filtered, this filter is propagated onward to the Winesales fact table:-
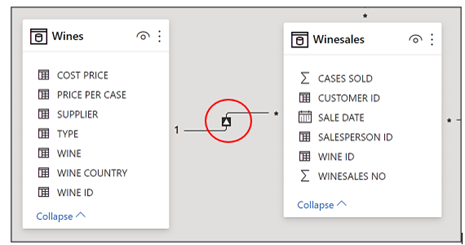
So the Winesales fact table is now cross-filtered to only contain sales for “Bordeaux” wine (i.e. WINE ID “1”). Notice there is no filter in the WINE ID column in the Winesales table because this is a cross-filter which is only generated because of the filter propagation:-
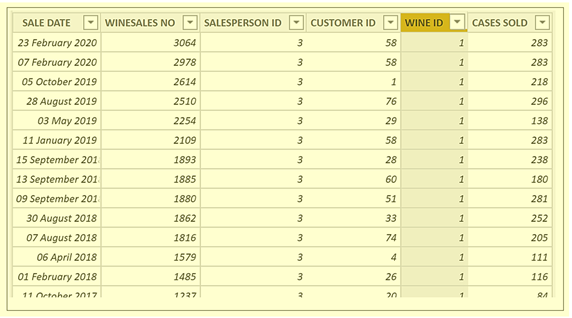
This is the only filter affecting this visual so the measure now sums the CASES SOLD column for “Bordeaux” wines and returns 39.627.
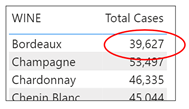
The evaluation of the measure then moves on to “Champagne” and repeats the process of filtering the Wines dimension and cross-filtering the Winesales fact table using a different filter context i.e. the WINE column from the Wines dimension now equals “Champagne” and so now returns 53,497:-
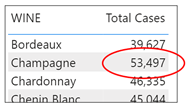
And so on for all the wines in the WINE column of the Table Visual. Every evaluation of the “Total Cases” measure has a different filter context.
Calculation in the Total Row
This now brings us to the calculation for the Total row of the visual, 605,854.
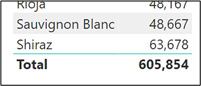
This value is not the sum of the values above. When the measure is evaluated for the Total row, all the wines are filtered in the Wines dimension, so the expression is evaluated for all wines. In other words, it’s our expression….
= SUM ( Winesales[Cases Sold] )
…..calculated in yet another different filter context.
Let’s create some more filters that affect the visual. So for instance, we could include a slicer using the SALESPERSON column from the Salespeople dimension and also a have the REGION column from the Regions dimension in a page filter.
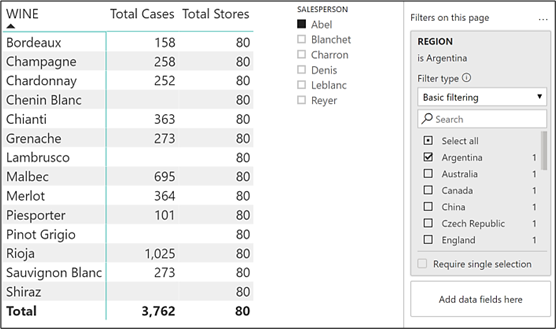
We’ve filtered salesperson “Abel” and region “Argentina”. You can see that the Total Cases value for “Bordeaux” is now 158 because the filter context has changed; wine equals “Bordeaux”, salesperson equals “Abel” and region equals “Argentina”. This is how the Salespeople and Regions tables would look like in memory respectively:-

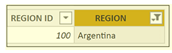
Note: The “Total Stores” measure is still returning the same value for every wine, although it’s now changed to 80. This is because the Customers table is now filtered to just customers in Argentina. We will explain more later.
If we look at the Data Model, we can see how these filters propagate through the Data Model and always arrive at the Winesales fact table.
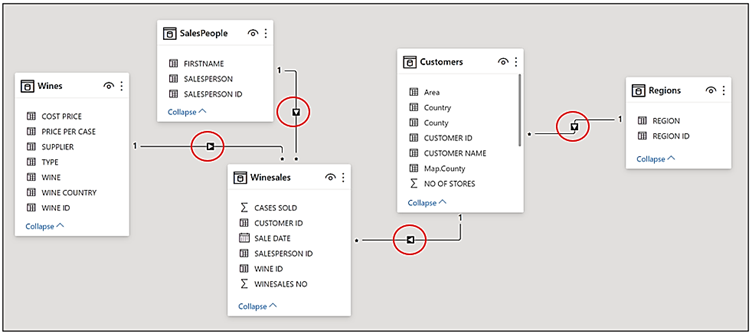
Notice how the Regions table creates a “snowflake” in the schema because it’s indirectly related to the Fact table via the Customers dimension. You can see how this arrangement of tables works; if the Regions table is filtered e.g. for “Argentina”, this filter is propagated through to the Customers dimension so customers in Argentina are now filtered. This filter is then propagated onwards to the Fact table.
Depending on how the visual is constructed and what filters affect the visual will determine the outcome of the measure. Which now brings us to the “Total Stores” measure in the visual below:-
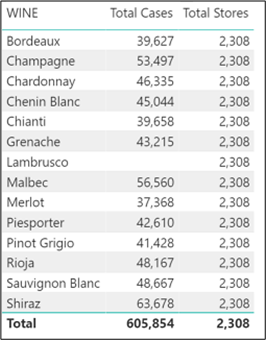
Total Stores = SUM ( Customers[ NO OF STORES] )
Notice it returns the same value of 2,308 for every wine and also in the Total row. This measure is summing the NO OF STORES column in the Customers dimension. The Customers dimension has no filter on it when this measure is evaluated. The only filter is on the Wines dimension. Therefore, for the evaluation of every wine, the measure sums the values in the NO OF STORES column in the Customers table for all the customers.
Looking again at the Data Model below, we can see that if the Wines dimension is filtered, this filter is propagated to the fact table (shown by the red tick) but the filter is not propagated onward to the Customers dimension (shown by the red cross), as the arrow only goes from the one side of the relationship into the many.
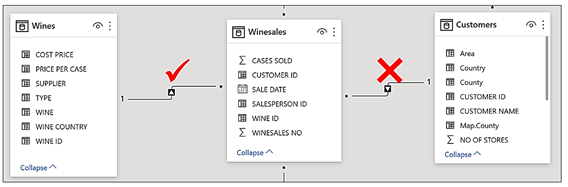
The filter context underpins all DAX measures and is the reason why it’s so important to distinguish between the two different types of table, dimension tables and fact tables because they play two different roles the evaluation of the measure:-
- The role of dimension tables is to group the data and to propagate filters into fact tables.
- The role of fact tables is to summarise subsets of data that have been cross filtered from dimensions.
DAX measures typically summarise data in the fact table that’s been cross filtered by dimension tables.
So next time you’re wondering, why is my measure incorrect, it’s not the measure at fault, it’s probably because you haven’t understood the filter context in which the measure has been evaluated. Remember this; always think FILTER CONTEXT!
Add new comment